[PATCH] Alpha code for Highway Symbols

Attached is alpha coding which enables graphical highway symbols in the map. See the attached screen shot for an idea of how this looks in mapsource (the symbols A5, B36, etc. now appear on the respective highways). Display looks similar on my e-trex. - The patch works only if the label file is written in 8-bit mode (use option --latin1 with mkgmap). As I am neither a Java programmer, nor familiar with Garmin's img format, the code is pretty rough. It consists of two parts: 1. An addition to the lines style file, which inserts the special code before the highway reference (hex 0x04 for motorways, 0x05 for major highways, 0x06 for minor highways). I had to use a hex editor to insert these symbols. 2. A hack in Element.java, which removes a space if it is the second character of the highway name. This is needed because only characters up to the first space will be displayed in the graphic symbol. That is, "A 5" would be displayed as only "A" in the highway symbol, so I change "A 5" to "A5" to get a reasonable symbol. The hack is obviously a poor solution, but it serves as a proof of concept. A clever regex would be much better here, as it should catch cases such as "SS 125", etc. Sorry for the poor quality of the code, but I did not have an Internet connection when I did this; I could not look up the proper way to do things in Java (such as regexes, string comparisons, constants, etc.). I would appreciate your comments. At least the patch makes the map look cool. ;-) Cheers.
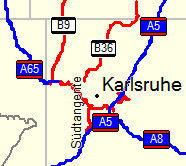{kind=link}

Hi Clinton,
1. An addition to the lines style file, which inserts the special code before the highway reference (hex 0x04 for motorways, 0x05 for major highways, 0x06 for minor highways).
I had to use a hex editor to insert these symbols.
cgpsmapper allows you to enter those codes using a syntax ~[0x??] but that doesn't seem to work with mkgmap. If it did, the binary editor would not be needed. Cheers, Mark

On Mon, Apr 06, 2009 at 12:44:54PM +0100, Mark Burton wrote:
Hi Clinton,
1. An addition to the lines style file, which inserts the special code before the highway reference (hex 0x04 for motorways, 0x05 for major highways, 0x06 for minor highways).
I had to use a hex editor to insert these symbols.
cgpsmapper allows you to enter those codes using a syntax ~[0x??] but that doesn't seem to work with mkgmap. If it did, the binary editor would not be needed.
What about \x04 (hex) or \4 (octal) or \u4 (hex, Unicode)? I have experienced that Java *.properties files allow the \u prefix for inputting Unicode code points. I don't know which method mkgmap uses for parsing the files. I'd vote for the \u syntax, as the files already are in Unicode (encoded to bytes in UTF-8). Marko

cgpsmapper allows you to enter those codes using a syntax ~[0x??] but that doesn't seem to work with mkgmap. If it did, the binary editor would not be needed.
What about \x04 (hex) or \4 (octal) or \u4 (hex, Unicode)? I have experienced that Java *.properties files allow the \u prefix for inputting Unicode code points. I don't know which method mkgmap uses for parsing the files. I'd vote for the \u syntax, as the files already are in Unicode (encoded to bytes in UTF-8).
\u Syntax is java Syntax, and is *NOT* UTF8-Encoding! Both of them are unicode, but the encoding scheme is different. At the moment it works fine, if you use an editor, which can handle unicode properly. But it is good idea, instead of introducing a new proprietary ~[xx] style, use a n existing standard, as e.g. the \u4 notation.
On Mon, Apr 06, 2009 at 02:38:15PM +0200, Johann Gail wrote:
\u Syntax is java Syntax, and is *NOT* UTF8-Encoding!
Correct. For example, \u2020 (the dagger symbol, †) would be \xe2\x80\xa0 or \342\200\240 in the UTF-8 encoding and \x20\x20 or \40\40 in UTF-16 (no matter if big or little endian, in this case). The octal and hex notation are 8-bit byte codes. I think that it is much more readable to write \u2020 for U+2020 than \xe2\x80\xa0. The \u notation will apparently also be in the next C and C++ syntax.
Both of them are unicode, but the encoding scheme is different. At the moment it works fine, if you use an editor, which can handle unicode properly.
I'm not sure if I understand your comment. I have understood that java.lang.String uses something like UTF-16 internally. I have never seen a text file containing Unicode characters that would be encoded in anything else than UTF-8. As far as I understand, the MySQL database (which I develop for a living) accepts UTF-16 string literals (called "ucs2"), but the bug reports I've seen always have been in ASCII, ISO 8859-1, or UTF-8.
But it is good idea, instead of introducing a new proprietary ~[xx] style, use a n existing standard, as e.g. the \u4 notation.
That exactly was my point. It should be trivial to implement all three notations (\x hex bytes, \ octal bytes, \u hex unicode). Marko
Both of them are unicode, but the encoding scheme is different. At the moment it works fine, if you use an editor, which can handle unicode properly.
I'm not sure if I understand your comment. I have understood that java.lang.String uses something like UTF-16 internally. I have never seen a text file containing Unicode characters that would be encoded in anything else than UTF-8. As far as I understand, the MySQL database (which I develop for a living) accepts UTF-16 string literals (called "ucs2"), but the bug reports I've seen always have been in ASCII, ISO 8859-1, or UTF-8.
See in the attached screenshot what I meant: Use an proper editor and store the file in UTF8 or whatever encoding of unicode. Then you don't need any workarounds as the \u4 to edit an unicode file.
{kind=link}

0> In article <4dda9d8f0904060426n7a65d517p33668c0706b872d@mail.gmail.com>, 0> Clinton Gladstone <URL:mailto:clinton.gladstone@googlemail.com> ("Clinton") wrote: Clinton> Attached is alpha coding which enables graphical highway Clinton> symbols in the map. See the attached screen shot for an idea Clinton> of how this looks in mapsource (the symbols A5, B36, etc. now Clinton> appear on the respective highways). Display looks similar on Clinton> my e-trex. Funnily enough, I've just been experimenting with the same thing here! Clinton> 1. An addition to the lines style file, which inserts the Clinton> special code before the highway reference (hex 0x04 for Clinton> motorways, 0x05 for major highways, 0x06 for minor Clinton> highways). I have a patch to ValueBuilder to read arbitrary hex characters: which mean my rules look like
highway=trunk {name '$[04]${ref} ${name}' | '$[04]${ref}' | '${name}' }
and so on. And for peaks,
natural=peak {name '${name}$[1f]${ele|conv:m->ft}' | '${name}' | '$[1f]${ele|conv:m->ft}' } [0x6616 resolution 18]
Clinton> Clinton> I had to use a hex editor to insert these symbols. Clinton> Clinton> 2. A hack in Element.java, which removes a space if it is the Clinton> second character of the highway name. Perhaps the hack should be to remove spaces (or replace with no-break-space (U+0080) if that works) in 'ref' values when substituting? And the non-hack to write a filter action to do so? I could have a look at this if you like.
On Mon, Apr 6, 2009 at 3:28 PM, Toby Speight <T.M.Speight.90@cantab.net> wrote:
Clinton> 2. A hack in Element.java, which removes a space if it is the Clinton> second character of the highway name.
Perhaps the hack should be to remove spaces (or replace with no-break-space (U+0080) if that works) in 'ref' values when substituting? And the non-hack to write a filter action to do so? I could have a look at this if you like.
Since I probably won't have time to work on this until the weekend, I certainly have no objections if you or anyone looks at this and proposes something better than my ugly hack. ;-) Regarding the syntax for hex characters in the style file, I wonder if allowing arbitrary hex chars is an appropriate solution. - As far as I know, there are a limited number of known control characters which make sense for inserting into element names. - The codes for the same symbols vary depending on the 6 or 8 (or 10?) bit encoding for the label file. This would mean that different style files would have to be used depending on the encoding options used when invoking mkgmap. - Would it be more elegant to have something like ${motorway-symbol} in the style file, and coding to make the appropriate translations? Of course, if there are many more potential hex-codes that could be inserted, this approach would be nonsense. It would also be unnecessary if using the same style file for 6 and 8 bit encoding is an unrealistic use case. What do you think? Cheers.
0> In article <4dda9d8f0904060852p6d70d32ci1878bb9f4e72e7bb@mail.gmail.com>, 0> Clinton Gladstone <URL:mailto:clinton.gladstone@googlemail.com> ("Clinton") wrote: Clinton> Regarding the syntax for hex characters in the style file, I Clinton> wonder if allowing arbitrary hex chars is an appropriate Clinton> solution. Clinton> Clinton> - As far as I know, there are a limited number of known Clinton> control characters which make sense for inserting into Clinton> element names. Clinton> Clinton> - The codes for the same symbols vary depending on the 6 or 8 Clinton> (or 10?) bit encoding for the label file. Do we have the encodings somewhere? I got my values from the GroundTruth manual page: <URL: http://wiki.openstreetmap.org/wiki/GroundTruth_Manual#Special_Symbols > Clinton> - Would it be more elegant to have something like Clinton> ${motorway-symbol} in the style file, and coding to make Clinton> the appropriate translations? Possibly - when you say "something like", obviously not that exact syntax, because of the conflict with value substition.
On Mon, Apr 6, 2009 at 6:47 PM, Toby Speight <T.M.Speight.90@cantab.net> wrote:
Do we have the encodings somewhere? I got my values from the GroundTruth manual page:
The initial information I found was in the Garmin IMG format document: http://sourceforge.net/projects/garmin-img/ However this document only lists the 6-bit encodings. The most complete document which I found was the cGPSmapper manual: http://cgpsmapper.com/manual.htm This document lists eleven codes, and gives both the 6-bit and 8-bit values. (There are nice pictures too.) For example, the large highway sign is ~[0x2d] in 6-bit and ~[0x04] in 8-bit. There are also codes for US highway symbols; apparently these labels can only be numeric, which presents another challenge for anyone wishing to implement these signs. Cheers.
This would mean that different style files would have to be used depending on the encoding options used when invoking mkgmap.
- Would it be more elegant to have something like ${motorway-symbol} in the style file, and coding to make the appropriate translations?
This was my thoughts too. I consider the special chars some garmin internals, where is no need to use them in the style file. On the other hand, the line style is also set in the style file, so it would be no difference with the special signs.
On Mon, Apr 06, 2009 at 02:28:07PM +0100, Toby Speight wrote:
Clinton> Clinton> I had to use a hex editor to insert these symbols. Clinton> Clinton> 2. A hack in Element.java, which removes a space if it is the Clinton> second character of the highway name.
Perhaps the hack should be to remove spaces (or replace with no-break-space (U+0080) if that works) in 'ref' values when substituting? And the non-hack to write a filter action to do so? I could have a look at this if you like.
Sorry for nitpicking, but the U+0080 refers to Unicode, and U+0080 to U+009F are control characters. The no-break space is U+00A0. I don't think that Garmin uses Unicode, though. It would be correct to say \x80 or 0x80 when referring to the byte. In UTF-8, anything above U+0080 would be encoded as multiple bytes. U+0080 would be two bytes, \xc2\x80. The cook book <http://www.maptk.dnsalias.com/Docs/Kochbuch.pdf> section 9.3 Zeichensatz (character set) mentions a few control codes: ~[0x1b2b] (my guess: \x1b\x2b) for forcing lower-case, ~[0x1b2c] for label separation (abbreviation?), and some single-byte codes. There's no mention of character sets supported by Garmin. Because a TYP file may contain labels in multiple languages (section 9.4 Sprachen), including Greek, Russian and Bulgarian, the Garmin character set(s) should include Latin, Greek, and Cyrillic glyphs. Has anyone tried to document the whole Garmin character set, including all escape codes? Or are there multiple character sets? Is the character set a per-map property, or is it per label? (Per-label would be good in the border areas of the Cyrillic, Greek and Latin Europe.) Marko
0> In article <20090406182837.GA4600@x60s>, 0> Marko Mäkelä <URL:mailto:marko.makela@iki.fi> ("Marko") wrote: Marko> The no-break space is U+00A0. Oops! My mistake. You're right that we don't know the complete Garmin character set(s) nor its (their) encoding(s), though...
I've made some progress on this, and have some code that can prefix tag values with characters thusly: #> highway=motorway {name '${ref|prefix:04} ${name}' | #> '${ref|prefix:04}' | '${name}' } or #> natural=peak {name '${name|def:}${ele|conv:m=>ft|prefix:1f|def:}' } #> [0x6616 resolution 16] Here's my code (I haven't yet set up Emacs to use TAB instead of 4 spaces for indenting this code, so don't consider this to be a proper patch just yet): I've still got some testing to do (for example, I've not tested "subst:" at all), but if anyone spots something to correct, please say so!
Here's a patch that I think I like. I've given it a reasonable exercise, including the error cases I could think of, and I didn't see any of the magic smoke escaping. If there are no issues, would someone commit it? Thanks.
On Tue, Apr 7, 2009 at 8:27 PM, Toby Speight <T.M.Speight.90@cantab.net> wrote:
Here's a patch that I think I like. I've given it a reasonable exercise, including the error cases I could think of, and I didn't see any of the magic smoke escaping.
I'll try to check out your patch. In the meantime, I have another related patch, which may be interesting for those wishing to use the highway symbols. I found out how to do regexes in Java, and added coding to Element.java which performs the following: - Removes the highway symbols from unreasonable names. (Names which are too long, non-numeric, etc.) - Removes spaces from names, so that they can be properly displayed as highway symbols (Changes "A 1" to "A1", "SR 32" to "SR32", etc.) This seems to correctly work for about 95% of all cases which I have encountered. The code is still a hack, and is far from optimal, but it may be useful when implementing a proper solution. I'd be interested in feedback. Cheers.
Your space-removal stuff isn't necessary with my patch: just add a 'subst' filter to the value: # highway=motorway {name '${ref|subst: =>.|prefix:boxx} ${name}' | # '${ref|subst: =>.|prefix:boxx}' | '${name}' } That replaces each space in ${ref} with a dot; to remove the spaces completely, use ${ref|subst: =>} - or, equivalently, ${ref|subst: }. Which would be best in the default rule-set? Would it be useful to have some sort of regular expression filter? I could code that up quickly enough, and it's probably cleaner than having magic in Element.java. Also, I forgot to mention when I posted my patch: I'd appreciate suggestions for better mnemonics for the magic characters; also if anyone knows how to code the 6-bit switch, I'd like some clues as to to how to find what encoding we're writing.
On Wed, Apr 8, 2009 at 8:42 PM, Toby Speight <T.M.Speight.90@cantab.net> wrote:
Your space-removal stuff isn't necessary with my patch: just add a 'subst' filter to the value:
Yes, I tried out the subst filter, but I liked regex approach for two reasons: 1. I can filter out unreasonable values for the highway signs. In such cases, I can remove the prefix code, so no sign will be displayed. 2. I can perform more complex pattern matching to remove spaces. Without the regex and using the subst rule, I get a number of roads that have improper symbols. See the attached screen shot for an example.
# highway=motorway {name '${ref|subst: =>.|prefix:boxx} ${name}' | # '${ref|subst: =>.|prefix:boxx}' | '${name}' }
That replaces each space in ${ref} with a dot; to remove the spaces completely, use ${ref|subst: =>} - or, equivalently, ${ref|subst: }. Which would be best in the default rule-set?
Hm... based on the results I get, it may be practical to leave this out of the default rule-set entirely for the time being. This rule could potentially cause undesirable side effects, and therefore should remain optional.
Would it be useful to have some sort of regular expression filter? I could code that up quickly enough, and it's probably cleaner than having magic in Element.java.
This could be interesting, but is it practical? I personally like regexes, but I'm not sure if this would find wider use. Would it be possible to easily include regexes in the style file, which are similar to the regexes I use in my patch? (Certainly the approach of hacking coding into Element.java is not appropriate.)
Also, I forgot to mention when I posted my patch: I'd appreciate suggestions for better mnemonics for the magic characters; also if anyone knows how to code the 6-bit switch, I'd like some clues as to to how to find what encoding we're writing.
I'll look into both of these. I found the coding for the 6/8 bit encoding the other day. I'll if I can locate it again. And thanks for your work here. The method of adding a non-binary prefix value in the style file is very helpful. I also like what you have done for the "natural=peak" POI. (Is it worth doing the same for natural=volcano?) Cheers.
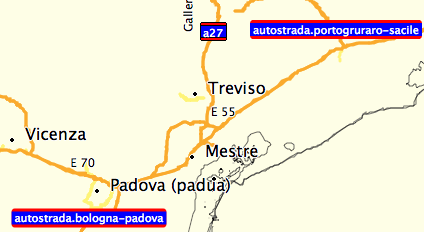{kind=link}
Sorry about the silence - I've just been away for a long weekend away from email. 0> In article <4dda9d8f0904090731s1e7647ebi7e1749c11cda7e93@mail.gmail.com>, 0> Clinton Gladstone <URL:mailto:clinton.gladstone@googlemail.com> ("Clinton") wrote: Clinton> Yes, I tried out the subst filter, but I liked regex approach Clinton> for two reasons: Clinton> Clinton> 1. I can filter out unreasonable values for the highway Clinton> signs. In such cases, I can remove the prefix code, so no Clinton> sign will be displayed. Clinton> Clinton> 2. I can perform more complex pattern matchING to remove spaces. Clinton> Clinton> Without the regex and using the subst rule, I get a number of roads Clinton> that have improper symbols. See the attached screen shot for an Clinton> example. Oh - are those really valid 'ref' values? I see what you mean, and I think the right way is probably to upgrade my simple 'subst' filter to handle regexps. Do you think that that would be the best solution? As I wrote:
Would it be useful to have some sort of regular expression filter? I could code that up quickly enough, and it's probably cleaner than having magic in Element.java.
Clinton> This could be interesting, but is it practical? I personally Clinton> like regexes, but I'm not sure if this would find wider use. Clinton> Would it be possible to easily include regexes in the style Clinton> file, which are similar to the regexes I use in my patch? That's what I was thinking of. The syntax would look something like #> highway=motorway {name '${ref|subst:^[\([AM]\) ?\([0-9]+\)$=>\1\2|prefix:boxx} ${name}' (for British and German motorways; it would need a little more knowledge to cover more 'ref' values.
I'd appreciate suggestions for better mnemonics for the magic characters; also if anyone knows how to code the 6-bit switch, I'd like some clues as to to how to find what encoding we're writing.
Clinton> I'll look into both of these. I found the coding for the 6/8 Clinton> bit encoding the other day. I'll if I can locate it again. I'm thinking that our best approach is going to be to use a single Java 'char' value in the action, then make the encoding translate that on output - I'll try and find time for that this week (if it rains!). Clinton> I also like what you have done for the "natural=peak" POI. (Is Clinton> it worth doing the same for natural=volcano?) I didn't spot the volcano one (and we don't have any near me). Sounds like a good idea.
On Tue, Apr 14, 2009 at 2:28 PM, Toby Speight <T.M.Speight.90@cantab.net> wrote:
Clinton> Without the regex and using the subst rule, I get a number of roads Clinton> that have improper symbols. See the attached screen shot for an Clinton> example.
Oh - are those really valid 'ref' values?
I think these are most likely incorrect 'ref' values, however they seem to occur frequently enough in certain maps to be annoying unless they are filtered out.
I see what you mean, and I think the right way is probably to upgrade my simple 'subst' filter to handle regexps. Do you think that that would be the best solution? [...] That's what I was thinking of. The syntax would look something like
#> highway=motorway {name '${ref|subst:^[\([AM]\) ?\([0-9]+\)$=>\1\2|prefix:boxx} ${name}'
I like this. :-) I just hope we don't keep extending the style syntax such that it some day becomes Turing complete. ;-) Thanks for your work on this. Cheers.
Sorry it's been a while, but I've been out mapping and Geographing in the nice weather! Anyway, here's the highway-symbol filter as promised:

On Tue, Apr 07, 2009 at 07:27:55PM +0100, Toby Speight wrote:
Here's a patch that I think I like. I've given it a reasonable exercise, including the error cases I could think of, and I didn't see any of the magic smoke escaping. If there are no issues, would someone commit it? Thanks.
I like the approach using a ValueFilter which keeps the code separate and used only when needed. However, I believe that building the functionallity out of prev and subst is too low level and it would be be better to have a single filter that does everything that is necessary to add the symbol; for example ${ref|highway-symbol=box}. I say this because not all of the special values go at the beginning of the string. Some of them are used to separate the parts of a streetname (eg between 'Main' and 'Street' in "Main Street"). Also the required regular expression to fix up the ref could get complex as shown in another message in the thread. The substitution filter might be a good thing to have for other purposes anyway. ..Steve
0> In article <20090418122018.GB31519@parabola.demon.co.uk>, 0> Steve Ratcliffe <URL:mailto:steve@parabola.demon.co.uk> ("Steve") wrote: Steve> I like the approach using a ValueFilter which keeps the code Steve> separate and used only when needed. Steve> Steve> However, I believe that building the functionallity out of prev Steve> and subst is too low level and it would be be better to have a Steve> single filter that does everything that is necessary to add the Steve> symbol; for example ${ref|highway-symbol=box}. Steve> Steve> I say this because not all of the special values go at the Steve> beginning of the string. Some of them are used to separate Steve> the parts of a streetname (eg between 'Main' and 'Street' in Steve> "Main Street"). Also the required regular expression to fix Steve> up the ref could get complex as shown in another message in Steve> the thread. Agreed - I've been thinking about this over the weekend (too sunny to sit inside coding!) and regular expressions don't fit inline very well - after all, the pipe symbol '|' is often needed in regexps, and it's already in use in the filter syntax. I think that coding the length check into a 'highway-symbol' filter as you describe above is probably the Right Thing. I'll produce a new patch this week. What are your thoughts on the elevation prefix? Another filter, that checks for a numeric value?
participants (6)
-
 Clinton Gladstone
Clinton Gladstone -
 Johann Gail
Johann Gail -
 Mark Burton
Mark Burton -
 Marko Mäkelä
Marko Mäkelä -
 Steve Ratcliffe
Steve Ratcliffe -
 Toby Speight
Toby Speight